Ji Woong (Brian) Kim1*, Ke Wang1*, Sirui Chen1, Zipeng Fu1, Cong Zhao2, Jeff Lai2, Chelsea Finn1,
1Stanford University, 2Meta

Robotics faces a fundamental challenge of data scarcity. Unlike language or vision research, there is no internet-scale dataset for robotic manipulation. A promising path forward is to leverage egocentric human data, which can be collected more easily, with greater breadth, and at a larger scale. Towards this end, we investigate key design choices for learning across human and humanoid embodiments equipped with dexterous five-finger hands, using the Pi0.5 model as a foundation. Our results show that human data enables robots to learn new task semantics and compose existing skills into novel behaviors without corresponding robot data.
(policies co-trained with human data)
Sorting 40 tomatoes in a row, 37 / 40 success rate
4x speed
Packaging 10 trials in a row, 9 / 10 success rate.
4x speed
Boxing 15 trials in a row, 14 / 15 success rate, policy trained with subtask generation.
4x speed
(policies trained only using robot data)
Sorting 40 tomatoes in a row, 16 / 40 success rate. The robot has no concept of sorting and places the tomatoes randomly.
The concept of sorting only appears in human data, which this baseline model was not trained on.
4x speed
Packaging 10 trials in a row, 1 / 10 success rate. The policy fails to learn the rule of
placing the black box at the bottom first. This rule-based ordering concept only appears in human data, which this baseline model was not trained on.
4x speed
Boxing 15 trials in a row, 4 / 15 success rate. The policy often attempts to open the box and reach for the block at the same time, without waiting
for the box to be fully open. The sequential ordering of these skills only appears in human data, which this baseline model was not trained on.
4x speed
We explore whether robots can learn high-level task semantics from human data. For instance, given a robot capable of basic manipulation skills, can we steer its behavior to learn a novel sorting rule, skill composition, and rule-based ordering just by co-training on such human data?
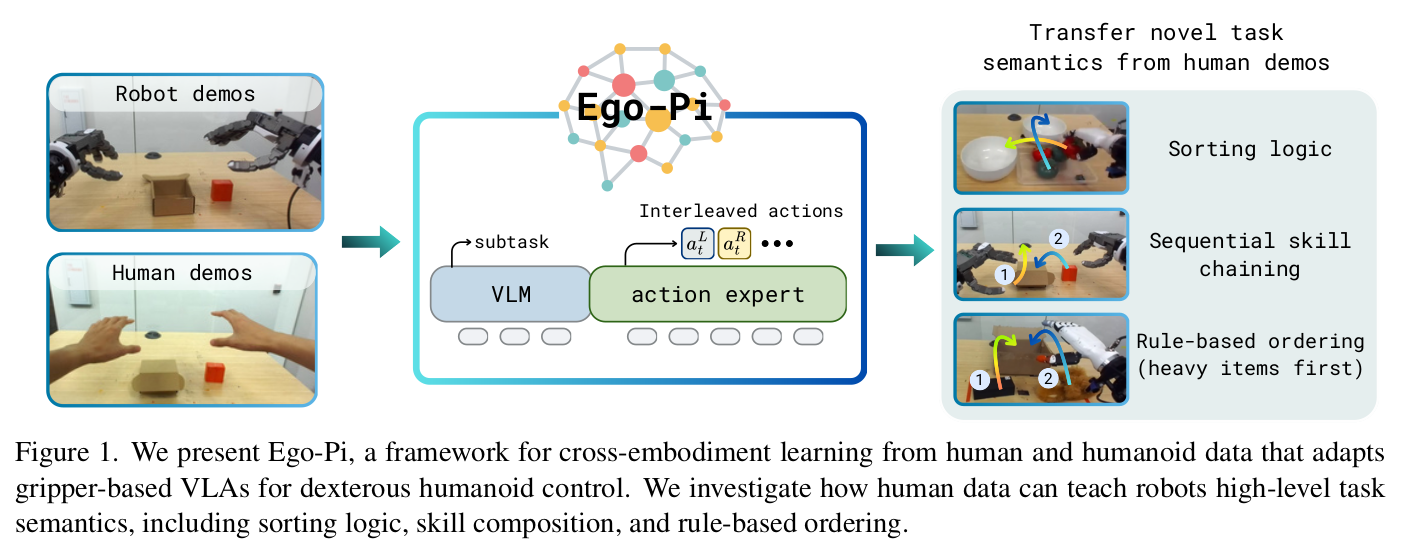
This could be useful feature because if you'd like to deploy your robot on a new task, but the new task is really just a novel composition of skills that the robot already knows, then you can just collect a small amount of human data for it without collecting robot data. For instance, think about cleaning up an unseen room, which might just require a composition of common pick-and-place skills, but performed in a specific sequence or preference.
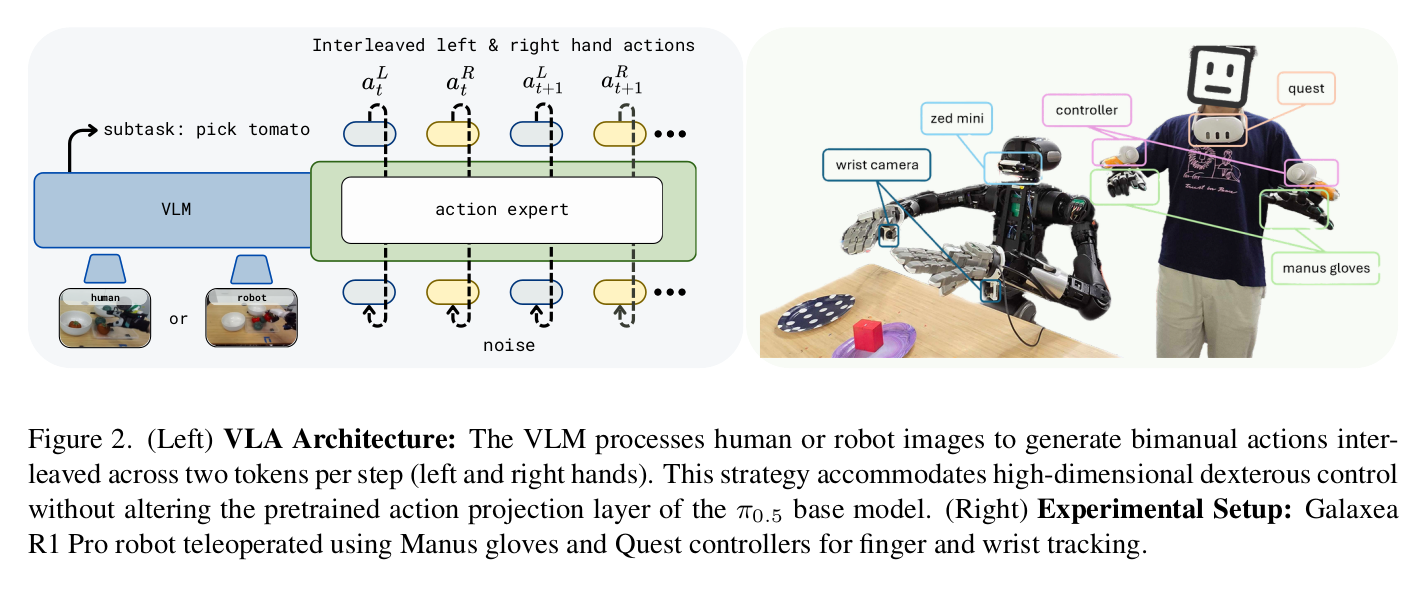
Fine-tuning Vision-Language-Action (VLA) models for humanoid embodiments presents a challenge: most state-of-the-art VLAs, such as Pi0.5, are trained on gripper-based robots with lower action dimensions than those required for humanoid platforms. For example, Pi0.5 has a maximum action dimension of 32. In contrast, our humanoid robot equipped with Tesollo hands requires 29 dimensions per hand (3 for position, 6 for rotation, and 20 for fingers), totaling 58 dimensions for both hands. While replacing the action projection layer with a larger one could accommodate this, it would require altering the model's pretrained weights. To preserve these weights, we instead distribute the 58-dimensional actions across two tokens. We interleave the actions, with the first token outputting 29 dimensions for the left hand and the second token outputting 29 dimensions for the right hand, repeating this pattern throughout the action sequence. Although this effectively reduces the action horizon by half, from 50 to 25 in the case of Pi0.5, we found this reduction to not an issue in practice.
Otherwise, the recipe is pretty straightforward. We co-train with human and robot data at a 50-50 ratio per batch, predict subtasks (though not always necessary for good performance), and align human and robot actions. Notably, we didn't even use wrist cameras for the human data.

We evaluated our approach on three benchmark tasks: tomato sorting, boxing, and packaging. For tomato sorting, the robot is taught the skill of picking up tomatoes, while human data provides the concept of sorting them by color into two separate bowls. In boxing, the robot is taught the independent skills of opening a box and picking up a block; human data then teaches the concept of sequencing these skills in the correct order. Finally, in packaging, the robot is taught to pick up a box and a teddy bear, with human data providing the concept of placing the box at the bottom and the teddy bear on top to complete the packaging sequence.
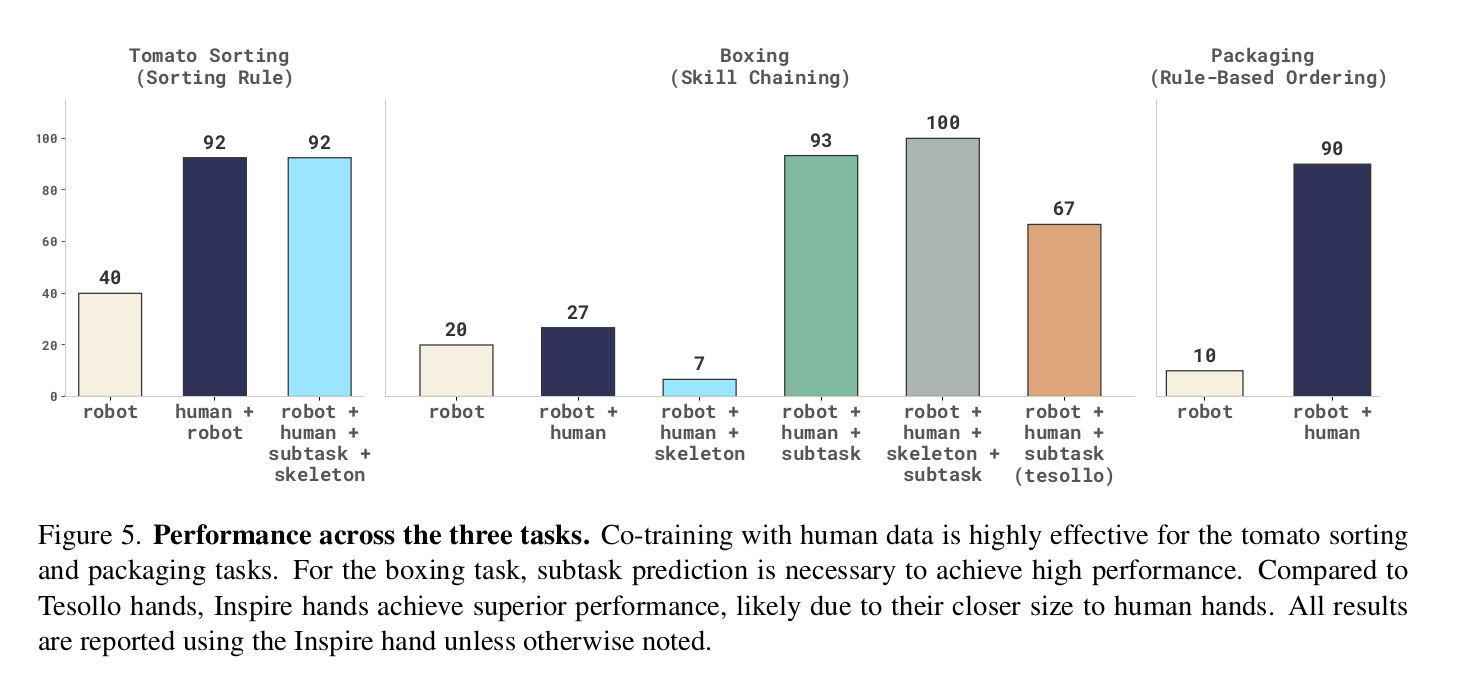
We found that simple co-training with human and robot data was quite effective in two out of the three tasks. Specifically, we were able to score a 37/40 success rate on the tomato sorting task, and a 14/15 success rate on the packaging task, but 4/15 in the boxing task. In order to do well in the boxing task, we needed to generate subtask instructions, likely because it required greater cognitive reasoning. We also experimented with visual augmentation such as drawing keypoints and lines across the robot and human images (i.e., skeletal lines), but this did not seem to improve the performance much. Also, despite the human data not having any wrist cameras, it was surprising that the robot was still able to learn the correct task semantics. The robot, however, still relied on the wrist images to do well on pick-and-place of objects, because if the wrist images were occluded, the robot did not perform well. We also found that the choice of the robot hand mattered. In particular, Inspire hands worked better than Tesollo hands in the boxing task, likely due to differences in the visual appearance and closer form factor to the human hand.
Overall, we demonstrated that teaching high-level task semantics through human data is feasible, enabling acquisition of novel skills and behaviors that exist only in human data. The humanoid robot could learn novel sorting logic, skill composition, and rule-based ordering with a sucess rate of 90% or higher. However, there are some limitations with our work. We explored relatively short-horizon, simple pick-and-place-oriented tasks in a fixed-camera scenario. Future work should evaluate the proposed ideas in more challenging scenarios, specifically long-horizon, dexterous manipulation tasks that require mobile manipulation. Additionally, human data should ideally teach robots low-level skills beyond high-level task semantics. In this work, we assumed that the robot was already capable of the necessary low-level skills, using human data primarily as a way to stitch these existing behaviors together in novel ways. Unlocking direct low-level skill transfer remains an open challenge that should be investigated further.
@article{kim2026egopi,
title={Ego-Pi: VLA Fine-Tuning for Ego-Centric Human and Robot Data},
author={Kim, Ji Woong and Wang, Ke and Fu, Zipeng and Chen, Sirui and Zhao, Cong and Lai, Jeff and Finn, Chelsea},
journal={arXiv preprint arXiv:2606.08107},
year={2026}
}